
CodeSearch——代码检索插件
Published:
本文将介绍一个根据功能检索代码的VSCode插件。
CodeSearch——代码检索插件
项目背景
在我们的项目中,常常会复用代码,而如果对已有代码不够熟悉,则很容易产生重复造轮子的情况。针对这样的情况,本项目旨在汇总已有代码组件、工具方法,使用信息检索的相关技术,实现一款能够根据功能检索代码的 vscode 插件,以方便大家的日常开发,减少重复造轮子的情况,提高效率。
项目内容
安装方法
- 下载打包后的.vsix 文件
- 将下载的文件放入 VScode 安装根目录的 extensions 文件夹中 文件夹路径参考:
Windows %USERPROFILE%\.vscode\extensions macOS ~/.vscode/extensions Linux ~/.vscode/extensions - 执行命令
code --install-extension xxx.vsix(建议 vsix 路径直接拖拽)
- 在 VScode 中调出命令搜索框,输入 code search,如存在此命令,则安装成功
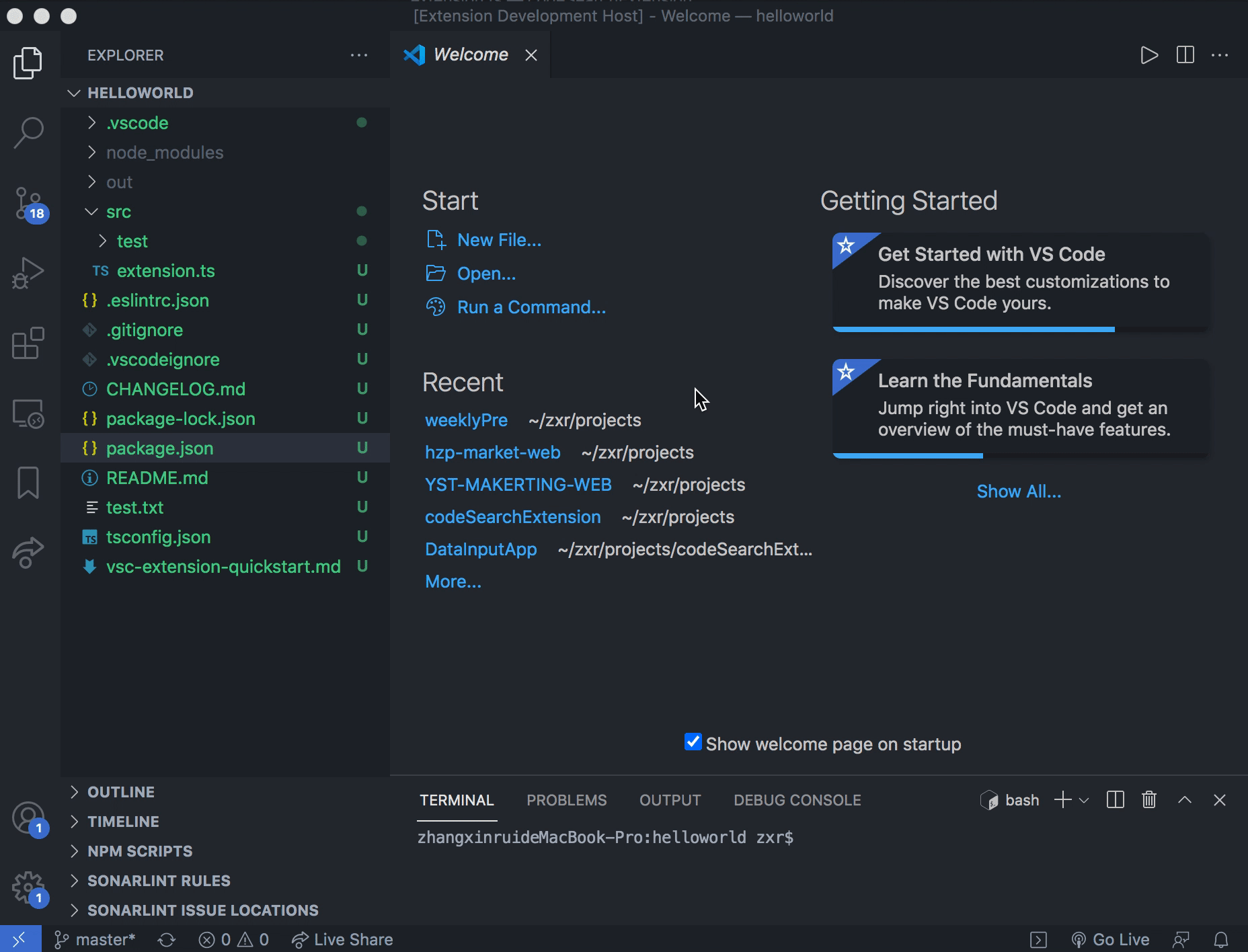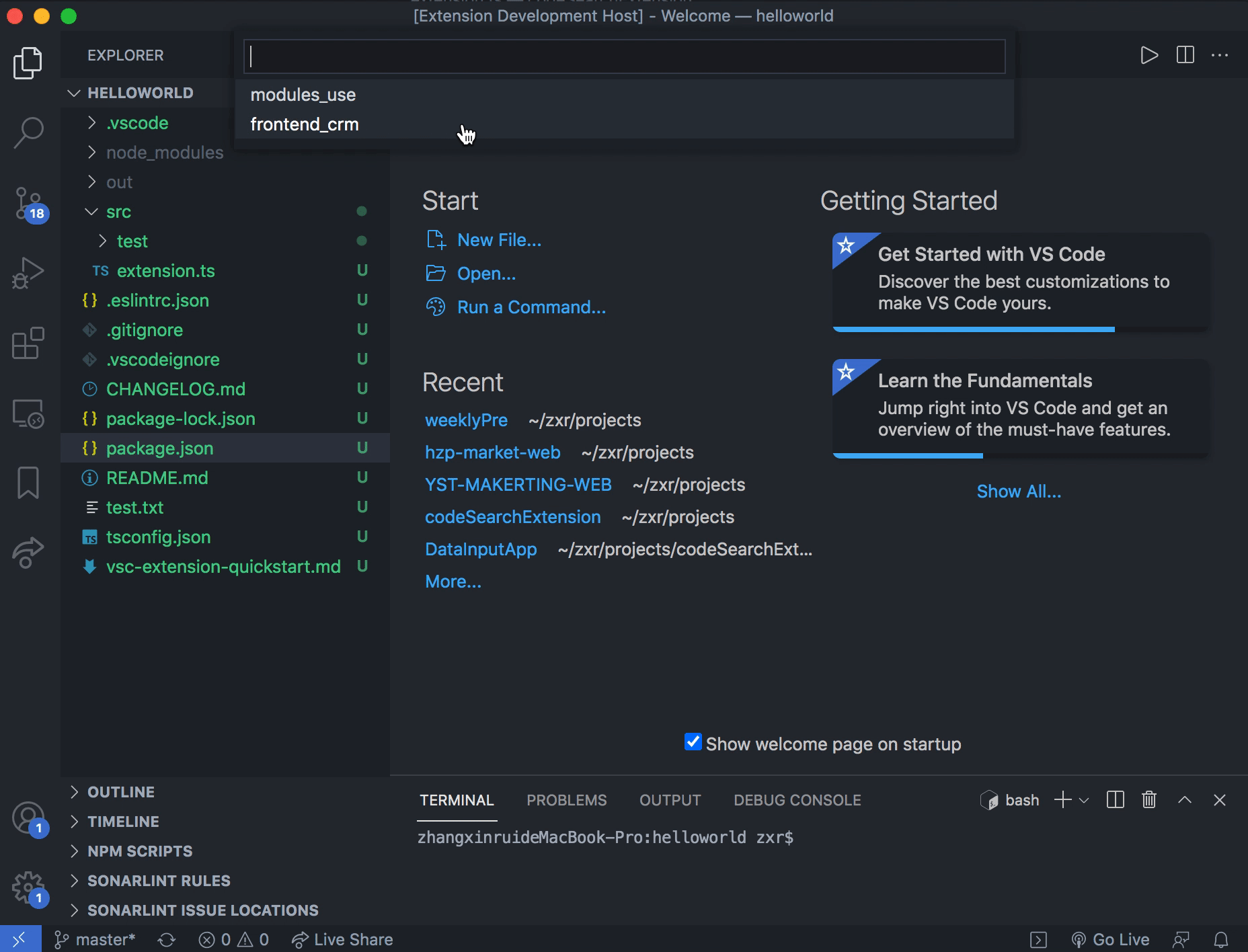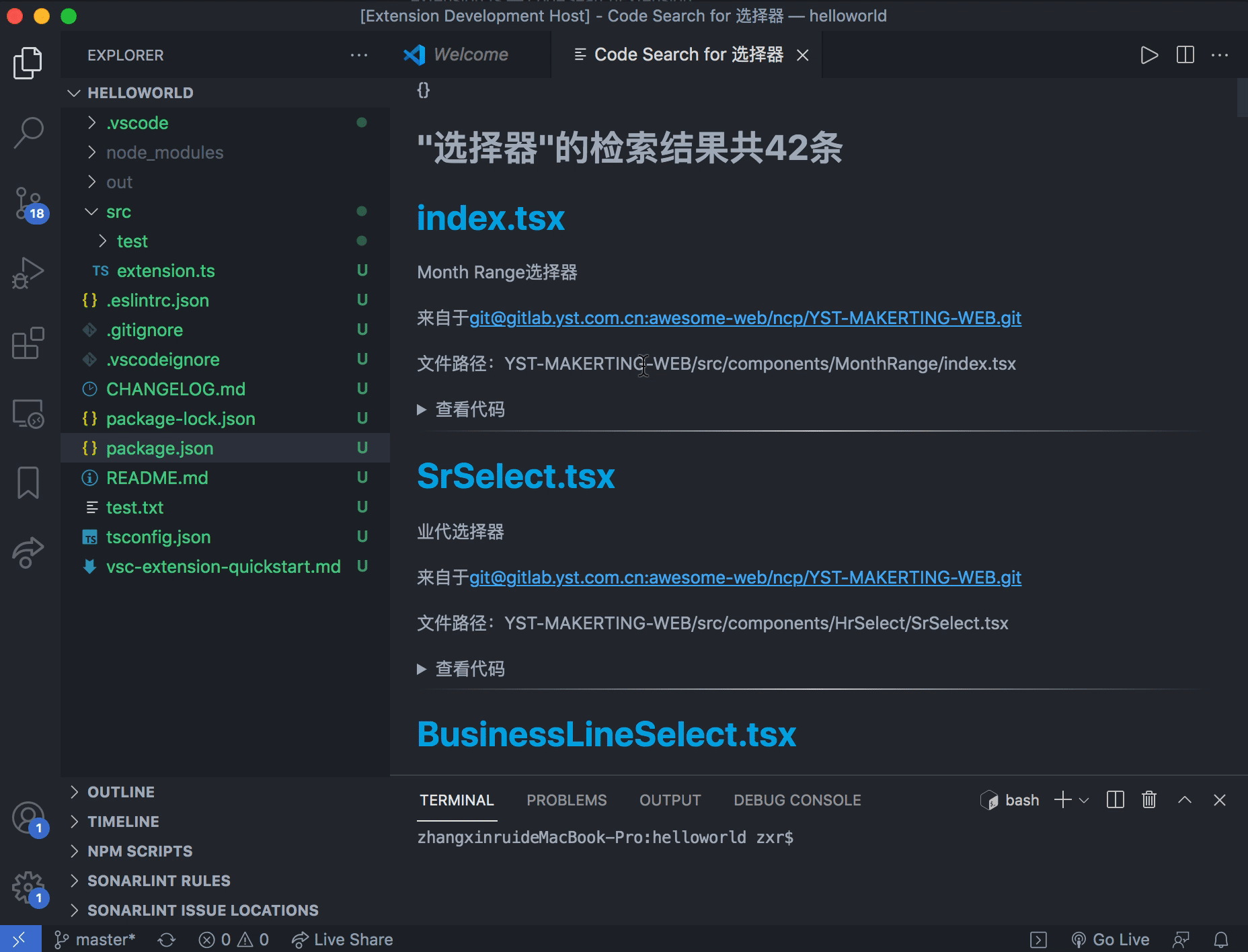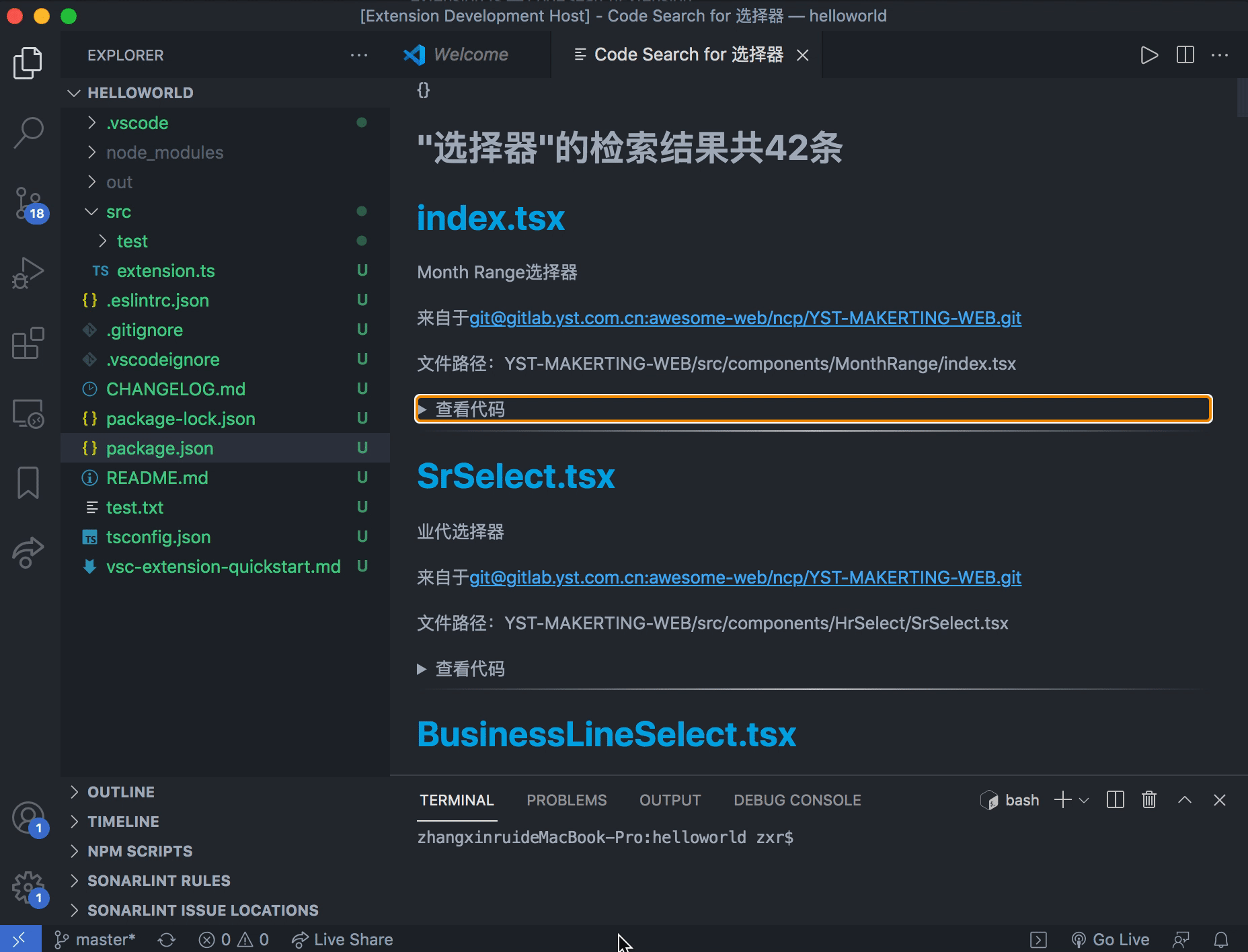
使用方法
- 在 VScode 中调出命令搜索框,输入或选择 code search
- 在接下来的下拉框中选择想要检索的范围
- 输入检索文本
- 查看检索结果
技术路线
本节中仅是概括性介绍,详细描述请参考后续段落。
typescript
用于 vscode 插件的开发。
参考资料:
elastic search
用于检索功能的实现。
参考资料:
electron
用于数据导入桌面程序的实现
参考资料:
特色与创新点
- 比起传统的搜索引擎,本项目的数据集对于与本组项目更有针对性,整合、汇总了本组已有资源,能更好地提高效率,并提供了加入个性化数据的服务。
- 相比于 VScode 已有的搜索功能,本插件在使用场景与功能上存在以下特点:
- VScode 搜索功能是针对本工作区内文件进行查找,适用于希望找到当前项目中某个变量、函数、代码段的场景;而本插件的检索数据集来源于本组多个项目的公共组件、工具函数,适用于在代码编写过程中,希望查找能实现某个功能的轮子的场景。
- VScode 搜索功能对搜索结果的排序并无特殊处理,而本插件将根据计算得到的相关度进行排序(具体公式参见下文)
- 本项目在数据采集的过程中,加入了对数据的分析、处理、可视化展示
所用技术介绍
VScode 插件开发
快速开始
根据接下来的步骤,我们可以创建一个使用命令激活,输出 hello world 的插件
安装 Yeoman 和 VS code generator
npm install -g yo generator-code脚手架——用于自动生成 VScode 插件模板项目
生成模板项目
yo code根据需要进行选择(若为首次尝试,可根据下列选项一路回车)
# ? What type of extension do you want to create? New Extension (TypeScript) # ? What's the name of your extension? HelloWorld ### Press <Enter> to choose default for all options below ### # ? What's the identifier of your extension? helloworld # ? What's the description of your extension? LEAVE BLANK # ? Initialize a git repository? Yes # ? Bundle the source code with webpack? No # ? Which package manager to use? npm运行 打开刚刚创建好的项目
code ./helloworldF5 运行项目调试
- 此时将打开一个新的 VScode 窗口用于插件调试,用于调试的窗口标题栏会标注”[Extension Development Host]”便于区分
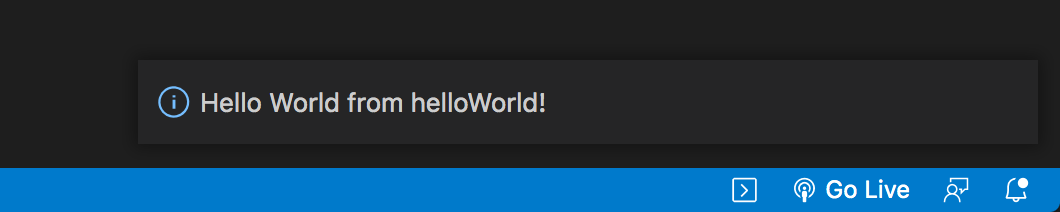
⬆+command+P 打开命令搜索框,输入 hello world,运行相关命令

在右下角看到弹出的通知框,即为命令运行成功,插件已激活
模板项目解析
根据上一节的步骤,我们成功创建了一个 VScode 插件,接下来,来看看这个项目中的结构与具体实现吧。
目录结构
.
├── .vscode
│ ├── launch.json // 插件加载和调试的配置
│ └── tasks.json // 配置TypeScript编译任务
├── .gitignore // 忽略构建输出和node_modules文件
├── README.md // 一个友好的插件文档
├── src
│ └── extension.ts // 插件源代码
├── package.json // 插件配置清单
├── tsconfig.json // TypeScript配置
针对基本功能的开发,我们目前只需要关注package.json和extension.ts这两个文件,如果你对其他配置文件感兴趣,可以查看 VScode 的官方文档 和 TypeScript 的官方使用手册。
插件配置清单-package.json
{
"name": "helloworld",
"displayName": "HelloWorld",
"description": "",
"version": "0.0.1",
"engines": {
"vscode": "^1.58.0" // 这里指定了插件运行所需的VScode版本
},
"categories": [
"Other" // 插件类型(具体见下一节介绍)
],
"activationEvents": [
"onCommand:helloworld.helloWorld" // 绑定激活事件
],
"main": "./out/extension.js",
"contributes": {
"commands": [
// 定义、发布命令helloworld.helloworld
{
"command": "helloworld.helloWorld",
"title": "Hello World"
}
]
},
"scripts": {
"vscode:prepublish": "npm run compile",
"compile": "tsc -p ./",
"watch": "tsc -watch -p ./",
"pretest": "npm run compile && npm run lint",
"lint": "eslint src --ext ts",
"test": "node ./out/test/runTest.js"
},
"devDependencies": {
"@types/vscode": "^1.58.0",
"@types/glob": "^7.1.3",
"@types/mocha": "^8.2.2",
"@types/node": "14.x",
"eslint": "^7.27.0",
"@typescript-eslint/eslint-plugin": "^4.26.0",
"@typescript-eslint/parser": "^4.26.0",
"glob": "^7.1.7",
"mocha": "^8.4.0",
"typescript": "^4.3.2",
"vscode-test": "^1.5.2"
}
}
源代码-extension.ts
// The module 'vscode' contains the VS Code extensibility API
// Import the module and reference it with the alias vscode in your code below
// 引入VScode提供的API
import * as vscode from "vscode";
// this method is called when your extension is activated
// your extension is activated the very first time the command is executed
// 当插件激活时执行此函数,激活条件即为package.json中注册的命令执行
export function activate(context: vscode.ExtensionContext) {
// Use the console to output diagnostic information (console.log) and errors (console.error)
// This line of code will only be executed once when your extension is activated
console.log('Congratulations, your extension "helloworld" is now active!');
// The command has been defined in the package.json file
// Now provide the implementation of the command with registerCommand
// The commandId parameter must match the command field in package.json
// 将package.json中定义的命令与对应事件注册绑定
let disposable = vscode.commands.registerCommand("helloworld.helloWorld", () => {
// The code you place here will be executed every time your command is executed
// Display a message box to the user
// 在右下角显示通知框
vscode.window.showInformationMessage("Hello World from HelloWorld!");
});
context.subscriptions.push(disposable);
}
// this method is called when your extension is deactivated
// 在插件停用前执行
export function deactivate() {}
最后,让我们来梳理一下,首先你需要在 package.json 中定义你将用到的命令,并注册能够激活组件的命令,如:输入命令”hello world”、打开 JavaScript 文件、按下组合按键等;接下来,在 extension.ts 的 activate 函数中将你定义的命令与将插件激活后命令触发的函数绑定起来,并在 deactivate 函数中进行插件停用前的清除,这样就可以实现一个简单的插件啦~
插件功能
上一节中,我们对 VScode 插件的结构进行了解析,几乎所有的插件都是根据这样的结构来进行开发的,本节中,我们将介绍 VScode 为哪些功能提供了可扩展的 API

VScode 插件可提供的功能主要为以上五类:
首先是通用的如选择文件、文件夹,收集用户输入,存储工作区或全局数据等基本的功能;
其次是主题相关的,如源代码颜色设置,UI 主题设置,icon 图标设置等;
第三是语言特性,分为声明式与程序式,声明式主要是文本编辑基础的特性,不包含代码逻辑,如括号匹配显示、自动缩进、语法高亮等,而程序式则需要结合程序语言逻辑,如悬停提示、跳转定义、格式化等;
第四是工作台 UI 的扩展,可以增加右键菜单、状态栏、侧边栏、webview 等,具体对应关系见下图;
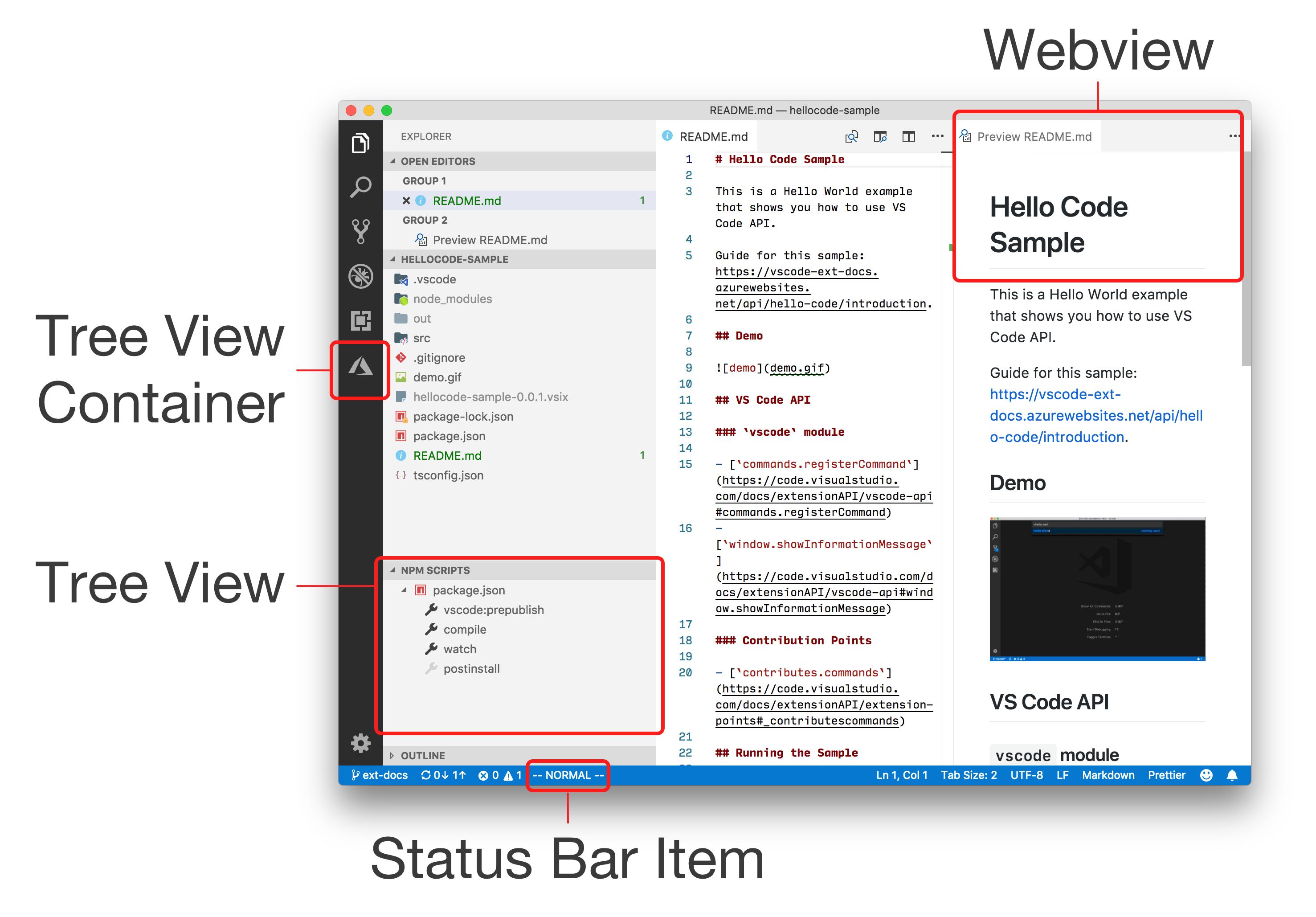
最后,是调试相关的功能,可以利用 VScode 提供的调试功能或自己的调试功能来进行开发。
以上仅为各类插件功能的概要介绍,具体的 API 见官方文档
VScode 命令系统
VScode 是微软使用 electron 框架,100%TypeScript 语言开发的桌面端代码编辑器软件,我们能够依照规范自由添加插件,主要源于其平台/插件架构风格的设计,下面将对 VScode 的设计做简要介绍

VScode 采用多进程架构,上图为简要展示,
- 主进程:VSCode 的入口进程,负责如窗口管理、进程间通信、自动更新等全局任务
- 渲染进程:负责一个 Web 页面的渲染
- 插件宿主进程:每个插件的代码都会运行在一个独属于自己的 NodeJS 环境的宿主进程中,插件不允许访问 UI
- Debug 进程:Debugger 相比普通插件做了特殊化
- Search 进程:搜索是一类计算密集型的任务,单开进程保证软件整体体验与性能

如上图,VScode 选取的命令系统相较网状的结构更为扁平,能够更加高效地进行功能的调用。
Elastic Search 与信息检索
本节将根据 elastic search 的原理,按照信息检索的一般流程对信息检索进行简要的介绍,旨在从较高层面了解大致流程,不会过多深入细节和具体实现。
数据采集
这一步是为后续的检索提供用于搜索的语料数据,并做预先的处理。
使用爬虫相关技术收集所需数据
数据清洗
- 去除空数据
- 去除重复数据
- 去除明显错误的数据
构建停词表、叙词表
停词表
无意义的标点、符号、字词等
叙词表

主要为同义词表
中文分词
由于中文没有自然的分隔符,相较于英文分词,难度更大,更易产生歧义,常使用字典、隐马尔可夫模型、机器学习等方法,不是本文的重点,故不做具体介绍。
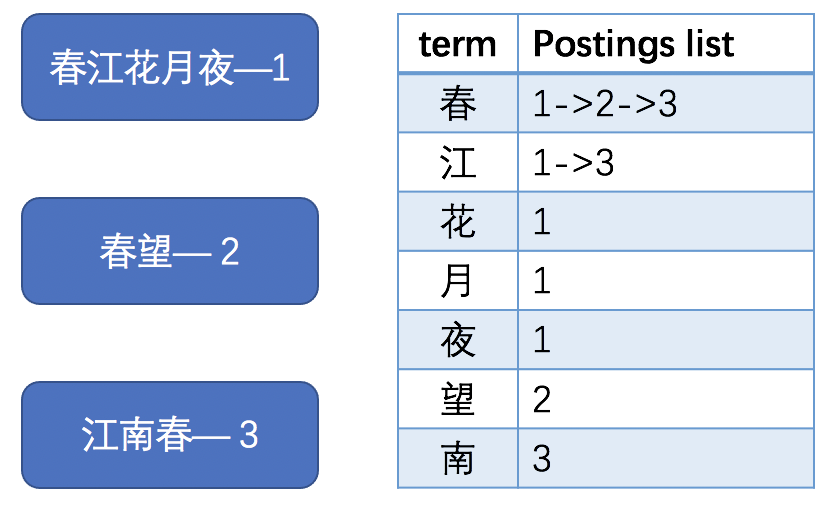
建立倒排索引
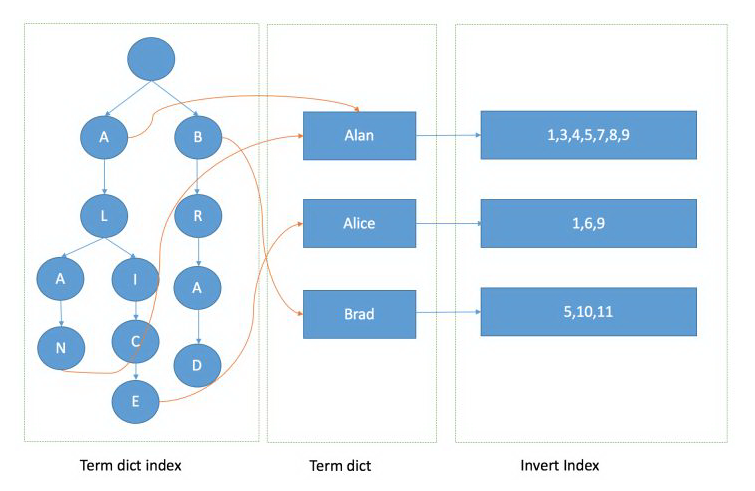
倒排索引是实现高效索引的关键,经过分词处理后得到的项作为 term 项,每项对应其所在文档编号的 postings list 倒排索引,如下图(例子中为方便举例,直接划分至字,没有进行分词)
同时,为了更高效地对 term 项进行检索,elastic search 采取了FST的结构,FST(Finite State Transducer)类似于 TRIE 树的结构,各 term 项可共用相同的前缀或后缀,但不同的 term 项到达结尾计算到的数值不同。
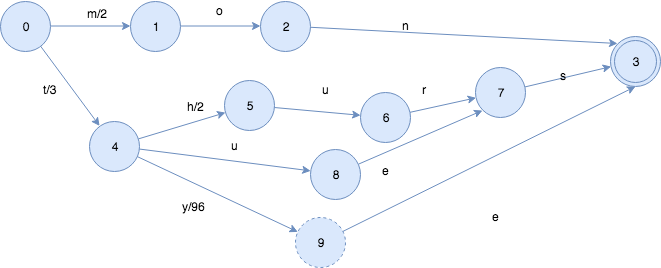
下图即为完整的 term dict index 词典索引树、term dict 词典、invert index 倒排索引的大致结构。
优化
对于大规模的信息检索,其数据量往往会达到十分庞大的程度,此时能否高效地存取也是影响检索效率的一个重要因素。针对这一问题,elastic search 采取了下列两种方法进行磁盘压缩存储与缓存查询优化。
Frame of Reference
此方法流程如下图,首先将文档列表处理为增量列表,然后将其划分为大小为 256 的块,然后进行按需分配,这里每块的第一位将记录块内各项所需的位数,之后各项根据最大项所需的位数存储。这样,就实现了压缩存储的倒排索引。

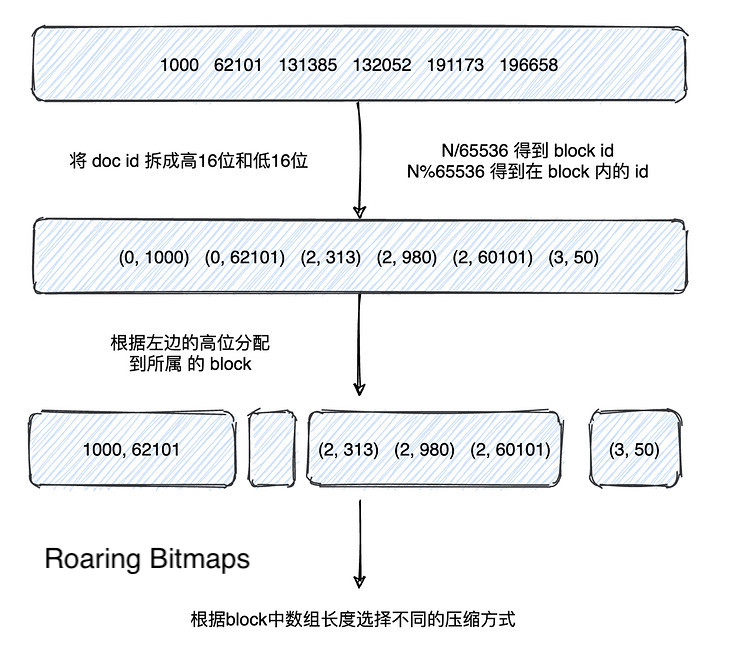
Roaring Bitmaps
上述的 Frame of Reference 方法很好地解决了倒排索引在磁盘中的存储问题,而对于分块存储的倒排索引来说,需要频繁的求并集,面对多条件查询时还需要进行交集操作,对于快速的交并集操作,elastic search 采用了 Roaring Bitmaps 的方法,在缓存中进行压缩。
在介绍 Roaring Bitmaps 之前,我们先来介绍两种压缩方法:
数组
也就是直接使用原始的文档 ID,进行数组操作,但这种方法显然不适合 elastic search 每次计算的数据量。
Bitmap
Bitmap 是一个常用的数据结构,我们通过一个例子来了解一下他的结构,我们现在有[2,3,5]和[1,3,4,5]两个数组,将其使用 Bitmap 来表示即为[0,0,1,1,0,1]和[0,1,0,1,1,1],也就是原数组中的值所对应的 Bitmap 中相应脚标的值为 1,其余为 0。这样如果我们要对两个数组取交集,那么我们就对他们的 Bitmap 做与运算,取并集,就做或运算。
我们看到 Bitmap 比较好地完成了对数组的压缩,无论原文档列表中各项的大小是多少,在 bitmap 中都只需要用一位的 0 或 1 来表示。事实上,相当长一段时间内,elastic search 都是采用这种方法的,直到 lucene5 开始使用 Roaring Bitmaps,这主要是为了解决 Bitmap 在稀疏情况下造成的空间浪费。
对于文档列表,使用 N/65536 得到该文档对应的块号,然后使用 N%65536 得到该文档在块内的 id,接下来根据不同的块号将文档分配的所属的块,最后根据块内文档数进行数组或位图的选择,这里的阈值来源于实际数据,当超过 4096 时选用位图,反之选用数组。
相关度计算
倒排索引让我们能够快速找到包含检索词的文档,但是当相关文档很多时,如果直接按照存储顺序呈现给用户,往往不会带来比较好的体验,我们需要计算文档与检索词的相关度,将最符合用户检索需求的结果排在靠前的位置。
为了进行相关度的计算,让我们先来了解几个参数
\[词频:tf_{t \in d} = \sqrt{frequency}\] \[逆向文档频率:idf_t = 1 + \log(\frac{numDocs}{docFreq+1})\] \[字段长度归一值:norm_d = \frac{1}{\sqrt{numTerms}}\]其中:
- $frequency$代表词 t 在文档 d 中出现的次数
- $numDocs$代表索引中文档数量
- $docFreq$代表包含词 t 的文档数
- $numTerms$代表所在字段的词数
由此,相关度计算公式如下:
\[score_{q,d} = coord_{(q,d)} * \sum_{t \in q}{tf_{t \in d} * idf_{t}^2 * Boost * norm_{(t,d)}}\]其中,$coord_{(q,d)}$为$\frac{文档中包含的查询词数}{查询词总数}$,$Boost$为设定参数
排序
上一节中,我们已经根据词频等数据计算得到了各篇文档的相关度,接下来需要对其进行排序,大量数据表明,按相关度降序排序后的前 20 条结果可以满足大多数用户的一般查询需求。因此,通常情况下我们不需要将全部查询结果返回给用户,只需要将前 K 个最符合查询需求的记录返回给用户即可,这里的 K 通常为 20。
这也就是十分常见的topK 问题,最基础的解法是将全部数据进行排序,然后取其前 K 个,但这种方法复杂度较高,在数据量比较大的时候并不适用。
一般来讲,我们采用最大堆/最小堆的方法,我们维护一个有前 k 个最大值构成的小顶堆,每拿到一个数据,就将其与堆顶数据比较,如果大于堆顶数据,则将堆顶数据删除,将新数据插入,反之则不做处理,这样当对全部数据遍历一遍后,堆中数据即为前 k 个最大值。若使用大顶堆,则开始遍历前对全部数据取反即可。
还可以使用快排的思想来解决 topK 问题,但其实现相对堆方法比较复杂,故本文不做介绍,感兴趣的朋友可以自行探索。
扩展阅读
注:本仓库为 private,如对源码感兴趣可以联系作者开放权限。
VScode 官方文档:https://code.visualstudio.com/api
VScode 源码:https://github.com/microsoft/vscode
MS 官方插件示例项目:https://github.com/Microsoft/vscode-extension-samples
TypeScript 官方文档:https://www.typescriptlang.org/docs/
TypeScript 类型体操:https://github.com/type-challenges/type-challenges
Elastic Search 官方文档:https://www.elastic.co/guide/index.html
常用中文停词表:https://github.com/goto456/stopwords