
ChatGPT 对软件开发技术的影响
Published:
《软件开发》课程报告
摘要
本文对ChatGPT进行了简要的介绍,根据其原理及功能特点,结合实例进行了ChatGPT在软件开发过程中各阶段应用的介绍,最终将这些应用分为客户交流类、知识咨询类、代码生成类、文档生成类、文本分析类五类,其主要侧重于重复性代码、文字的生成与基于知识的问答、交流工作,并提出了对于未来软件开发技术智能化发展的展望。
ChatGPT简要介绍
ChatGPT是由OpenAI发布的最新语言模型,由于其内部原理并未公开,我们通过他的前序模型和展示出的功能来推断他的技术路线,从而更为清晰地判断与评估其在软件开发中所能发挥的作用与产生的影响。ChatGPT的前身是GPT-3[@gpt-3],GPT-3通过上千亿单词的训练语料库,与充分的预训练任务,实现了能够通过上下文学习的语言生成功能,在多个数据集中达到了较好的性能,但与今天的ChatGPT相比,很难说GPT-3是智能的[@gpt],而之后基于GPT-3的模型与实验,展示了GPT-3有着非常强的潜力,在Instruct-GPT[@instruct-gpt]中,引入监督学习与基于人类反馈的强化学习指令微调后,模型可以生成更加符合人类期待的反馈,生成安全和公正的对话回复并拒绝超出模型它知识范围的问题。在ChatGPT中,其牺牲了几乎所有的上下文学习的能力来换取建模对话历史的能力,并提供了遵循人类价值观且包含更多细节的语言生成能力,拒绝知识范围外的问题。
从而,我们推测ChatGPT通过使用监督学习和强化学习的组合来进行调优,从而实现基于基础世界知识的中立、客观、安全、翔实的语言生成能力,同时能够建模对话历史,增加对话信息量。
ChatGPT在软件开发过程中的应用
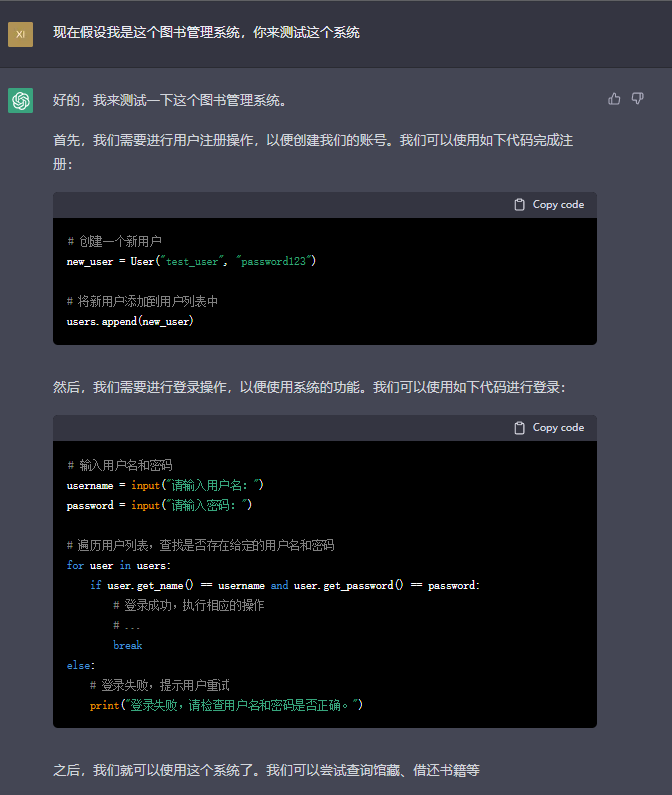
通过对ChatGPT来源历史和原理的介绍,我们知道ChatGPT通过使用超大规模训练语料库,结合基础世界知识,存储大量知识,在对话中使用模型知识进行语言生成,同时通过基于人类反馈的强化学习指令微调,实现生成语句的中立、客观、安全、翔实,并支持对于对话历史的建模,对于长对话的支持好,能够保留长对话中的历史信息量。在软件开发中,这种语言模型能够在软件智能化开发的各个阶段提供支持与影响。现有基于大数据的软件智能化开发方法在软件开发的软件构造、测试验证、群体协作、运维演化各个阶段均有涉及[@all]。ChatGPT作为一个新兴的智能语言生成模型,其在训练时包含了大量的现有基础世界知识,并有有效、符合逻辑的语言生成能力,在现有软件开发方法及过程中,笔者认为在需求分析、软件设计、编码构建、软件测试、运维部署各个阶段均有对应的应用,同时还可提供软件开发全过程的文档辅助生成功能,接下来将以一个图书管理系统的开发为例,详细介绍ChatGPT在软件开发各个阶段的应用。
需求分析
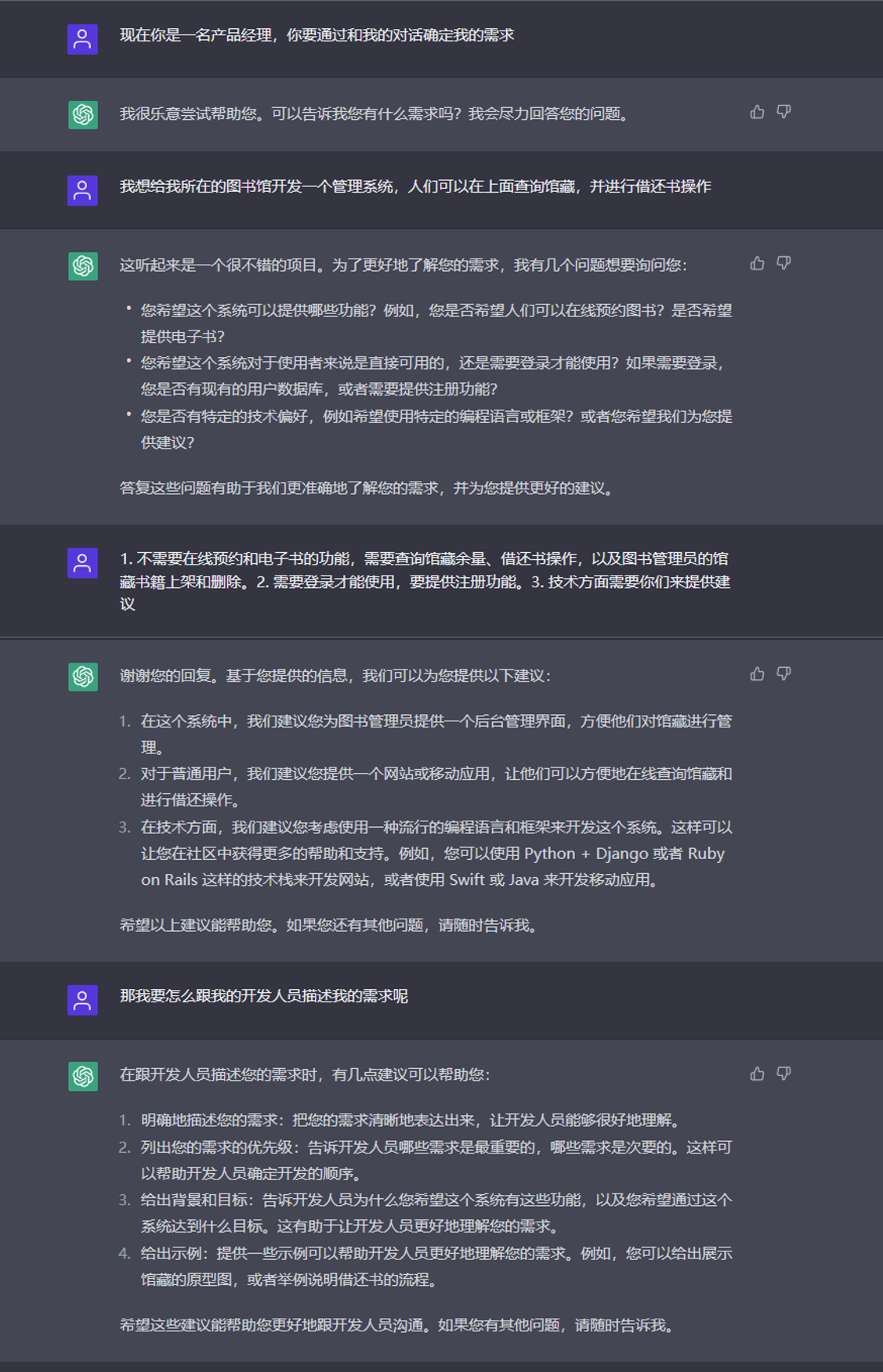
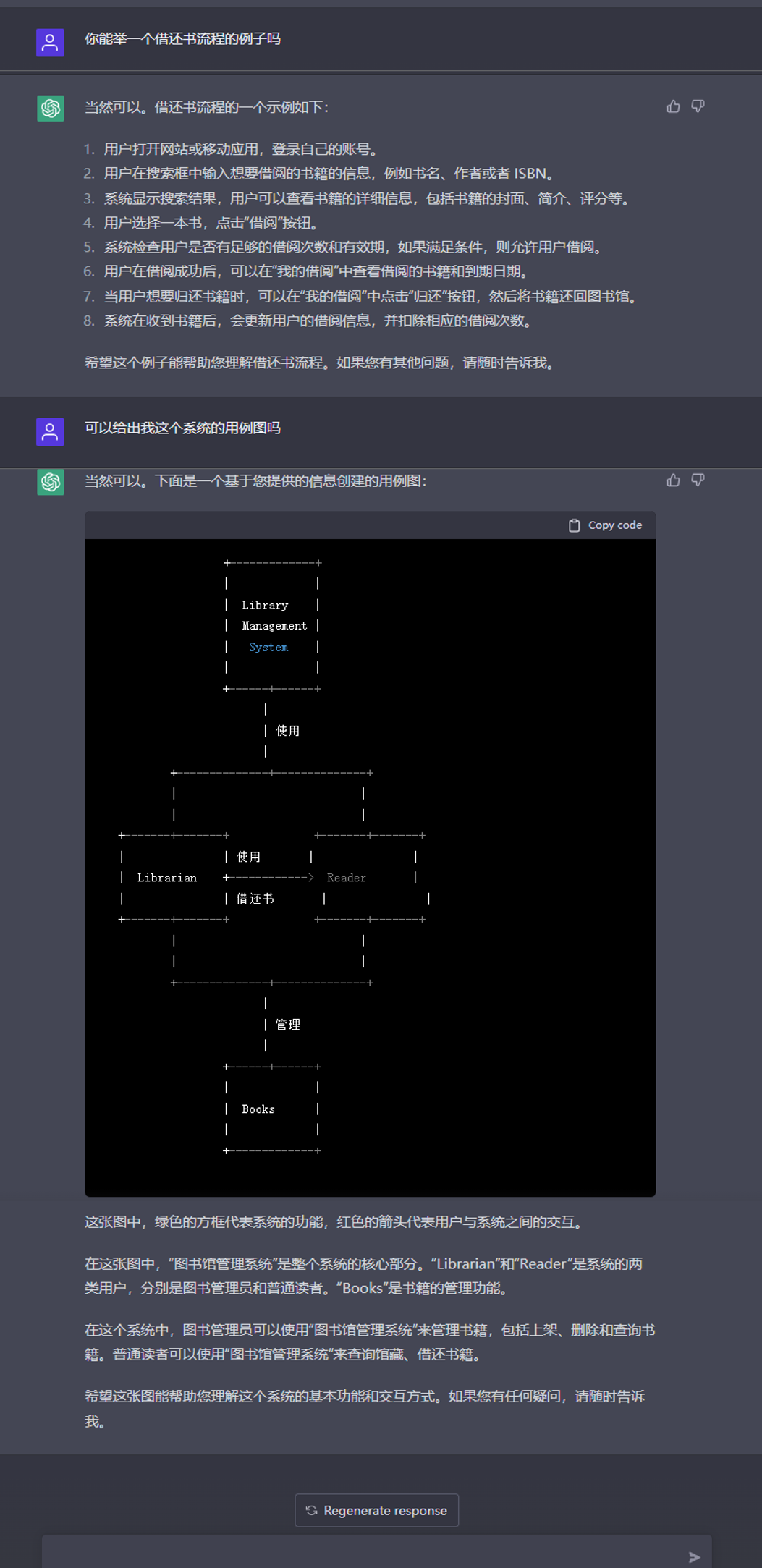
需求分析涉及到与客户的多次交流,这些交流是使用自然语言进行的,现有软件开发过程中这一步骤多由产品经理进行,产品经理需要引导客户表达自己的需求,然后将其整理成为符合软件开发实际的表述方式(如可以使用用例图、活动图等UML图),再与软件开发人员进行沟通。现有工作[@demand]使用自然语言处理的文本分析法进行需求文档的形式化验证,而如今的ChatGPT对于对话历史的建模,使其对于长对话有较好的支持,能够记忆长对话中前几轮的对话内容,并在后续对话过程中融入前期对话信息,可以作为产品经理与客户沟通交流的辅助,从图1中可以看出,ChatGPT在对话中有引导客户补充完善需求的意识,能够引导客户思考需求;同时,如图2,ChatGPT能够总结长对话前文中的内容,形成如图中的用例图一样的形式化表述,虽然图中对话形成的用例图还不够完善,但其对于对话的掌握情况是比较全面的,可以为产品经理的工作提供辅助,未来对于ChatGPT的预训练模型进行进一步的下游任务微调,增强其总结归纳形式化的能力,有可能替代产品经理与客户进行前期沟通,人力仅需在对话完成后对记录进行检查确认即可。
软件设计
同时,由于ChatGPT拥有大量的基础世界知识,可以在软件设计过程中,充当更为便于沟通的搜索引擎的角色,它能基于已有的模型知识,调动自然语言处理能力,理解用户的问题,然后已有知识中搜索、寻找符合问题的答案,然后将其组合形成符合语言逻辑的答案。但值得注意的是,ChatGPT只能辅助充当简洁的搜索引擎,其对于软件设计这一复杂、需要经验且可能有多种答案进行权衡的工作,ChatGPT所给出的答案并不一定是最优的,其只能作为相关人员的参考知识辅助,不能直接进行这一阶段的决策。
编码构建
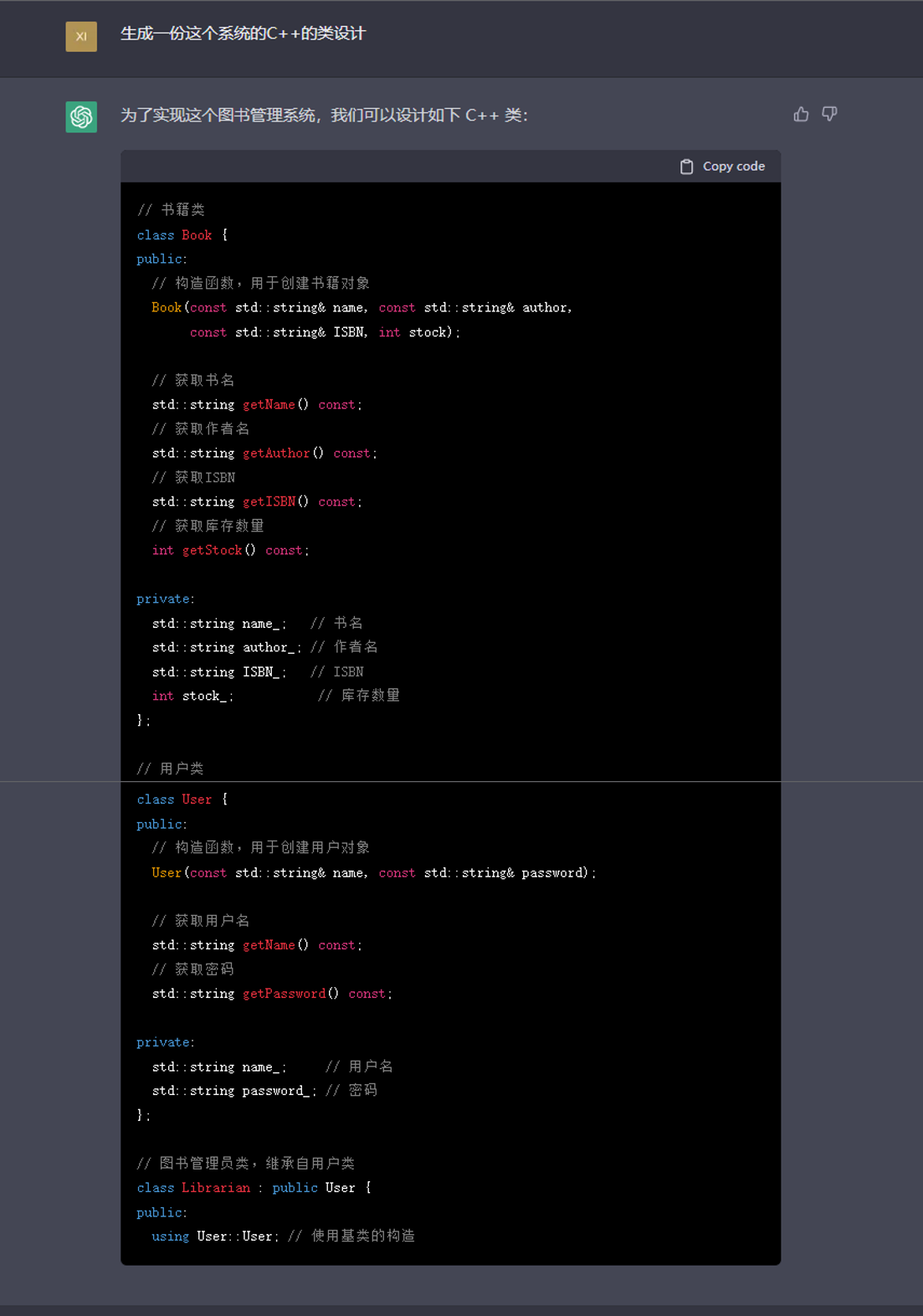
由于ChatGPT对于语言生成的符合逻辑,除了自然语言,它也可以生成代码,但受限于其对于自然语言转换代码理解的有限性,以及代码后续维护的可读性、健壮性,以及模型的语言生成需要依靠他的知识范围,对于超出它知识范围的问题或内容他是不能生成的,所以我们更多可以使用ChatGPT生成简单的代码,如重复性高的代码一类,用于减轻开发人员的负担,但对于创造性比较高的代码,则不适合使用ChatGPT来进行生成,如果直接使用ChatGPT生成复杂的生产代码,则非常容易在测试用例不充分的情况下,埋下隐患,后续维护人员也很难快速定位bug。这一方面与现有工作[@code]能起到的作用比较相近。
同时,也可以使用自然语言处理相关模型,对代码进行简单的注释生成,减轻开发人员的工作量,提高代码的规范性。
软件测试
在软件测试方面,目前已有工作使用机器学习、深度学习方法进行代码的静态分析[@codereview],这一功能ChatGPT同样也可以支持,如图5中,即为ChatGPT对一段代码进行简单分析,其优势在于能够支持多种语言多种框架的代码的简单分析,但也存在针对性不够,检查不全面的问题,因此可以在代码审查时,加入ChatGPT检查的步骤,为后续的代码审查提前去掉一些低级错误。

同时,比起对代码进行理解检查,ChatGPT更擅长生成类的问题,如图6中即为生成测试用例和测试代码,可以通过这一自动化生成的方式减轻测试人员的负担,但以怎样的问题和表述向ChatGPT描述需测试的系统或功能,需要有经验且了解ChatGPT机制的测试人员来进行构建,因此ChatGPT可以在软件测试过程中帮助测试人员构建测试用例,这里的测试用例主要为简单、模式化的、重复性高的测试用例,用于减轻测试人员的工作量,但向ChatGPT的输入以及比较个性化定制化的测试用例还是需要测试人员人工完成。
运维部署
一方面,与在编码构建阶段类似,ChatGPT可以用于生成一些部署的模板性重复性代码;另一方面,如图7,在后续的运维阶段,ChatGPT在代码生成方面的能力,可以用于进行代码重构,即进行不同编程语言之间的翻译,目前已经有很多工作利用自然语言处理的预训练模型加以微调,从而用于代码的翻译[@re],但与编码构建阶段的代码生成类似,如果要直接将生成或翻译的代码用于生产,无论是已有的代码翻译工作,还是现在的ChatGPT,都可能会埋下较大的隐患,所以如近期提出的工作一样,这些代码翻译工作可以考虑加入人工,进行人机协同的代码翻译[@rehuman]。

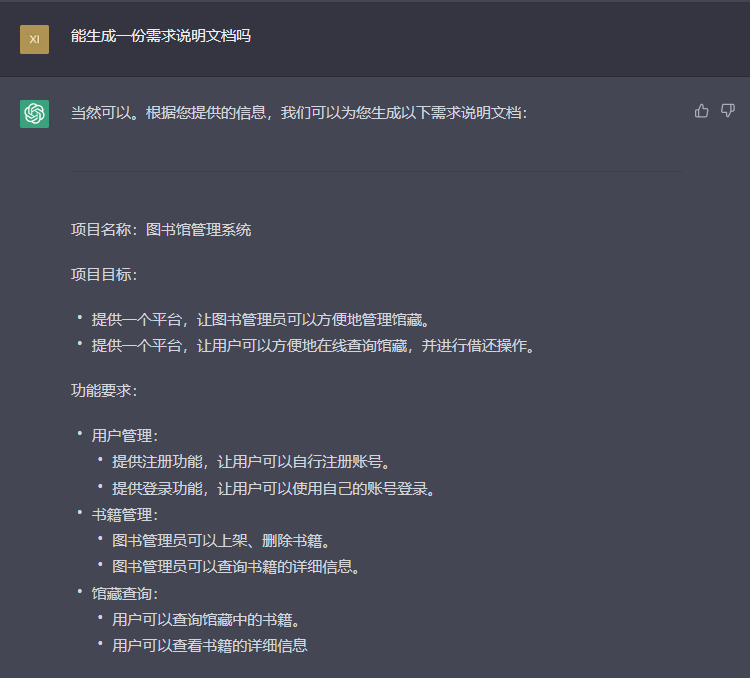
文档生成
如图8,ChatGPT强大的语言生成能力,可用于软件开发过程中各种文档的生成,可以减少开发人员撰写文档时的一些重复性、机械化的工作,这也有过相关工作[@doc]进行API文档的生成,但其主要依赖代码的模式化进行生成,自由度较ChatGPT更低。
思考与展望
总结来看,ChatGPT在软件开发的各个阶段均可有所应用,根据现有文献与实例,本文将其分为以下几类:
客户交流类
这类应用运用了ChatGPT对长对话的良好记忆与运用能力,可以用于与客户的使用自然语言的沟通,从而协助相应人员进行沟通交流的总结归纳,多用于软件开发的需求分析阶段。
知识咨询类
这类应用主要依靠ChatGPT在预训练阶段融入的大量基础世界知识,可以作为搜索引擎的精简版使用,但也受到预训练时给出知识的范围和选择,不能完全替代搜索引擎,可供相关人员在软件开发的各个阶段辅助使用。
代码生成类
这类应用运用了ChatGPT的语言生成能力,能够生成合逻辑的基本正确的代码,但不能保证生成的代码是完全正确的符合需求的,不能直接应用于生产环境中,可能会埋下隐患,需要谨慎权衡使用,可用于编码构建、运维部署、代码重构等阶段。
文档生成类
这类应用同样运用了ChatGPT的语言生成能力,可以根据系统或功能生成软件开发过程中的文档,但由于文档内容依赖于向ChatGPT的输入内容,因此这类应用更适合生成重复度较高的模式化文字,具体内容由相关人员人工添加可能会效率更高,这类应用可用于软件开发的各个阶段。
文本分析类
这类应用运用了ChatGPT对文本的理解能力,可以用于对代码审查,但由于在正确性方面,模型的判断依赖于它预训练时的大规模知识,因此不能完全替代代码审查工作,仅可作为人工的辅助,可用于软件测试阶段。
总体来看,ChatGPT这类语言模型更适合进行一些机械性、重复性代码、文字的生成与基于知识的问答工作,这有助于在软件开发过程中减轻相关人员的重复性工作,而相对具有创造性的工作如核心代码的编写,虽然ChatGPT可以给出答案,但并不能够完美满足需求,且容易埋下隐患,在生产环境中并不适用。在作者看来,随着大数据、人工智能的发展,未来软件开发有向智能化发展的趋势,能够降低开发人员在重复性工作中的工作量,同时能够融合更多知识来进行决策的辅助,如智能需求分析、代码生成、开发人员选择等,但开发人员对于业务的理解、对于开发过程所积累下的独有的经验是机器较难学习到的,这些更具创造性的工作人工智能只能作为辅助,最终的决策还是需要人来完成。
参考文献
[1] BROWN T, MANN B, RYDER N, et al. Language Models are Few-Shot Learners[C]// Advances in Neural Information Processing Systems: volume 33. Curran Associates, Inc., 2020: 1877-1901.
[2] FU H, Yao; Peng, KHOT T. How does gpt obtain its ability? tracing emergent abilities of language models to their sources[J]. Yao Fu’s Notion, 2022.
[3] OUYANG L, WU J, JIANG X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
[4] 谢冰, 彭鑫, 尹刚, 等. 基于大数据的软件智能化开发方法与环境[J/OL]. 大数据, 2021, 7(1): 3. DOI: 10.11959/j.issn.2096-0271.2021001.
[5] 杨新生. 基于自然语言处理的软件需求验证研究[D]. 上海交通大学, 2019.
[6] CHEN C, PENG X, SUN J, et al. Generative API usage code recommendation with parameter concretization[J]. Science China Information Sciences, 2019, 62(9): 1-22.
[7] WANG Y, WANG L, YU T, et al. Automatic detection and validation of race conditions in interrupt-driven embedded software[C/OL]//Proceedings of the 26th ACM SIGSOFT Inter- national Symposium on Software Testing and Analysis. Association for Computing Machinery, 2017: 113–124. DOI: 10.1145/3092703.3092724.
[8] LACHAUX M A, ROZIERE B, SZAFRANIEC M, et al. DOBF: A Deobfuscation Pre-Training Objective for Programming Languages[C]//Advances in Neural Information Processing Sys- tems: volume 34. Curran Associates, Inc., 2021: 14967-14979.
[9] WEISZ J D, MULLER M, HOUDE S, et al. Perfection not required? human-ai partner- ships in code translation[C/OL]//26th International Conference on Intelligent User Interfaces. Association for Computing Machinery, 2021: 402–412. DOI: 10.1145/3397481.3450656.
[10] LIN Z, ZOU Y, ZHAO J, et al. Improving software text retrieval using conceptual knowledge in source code[C]//2017 32nd IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 2017: 123-134.